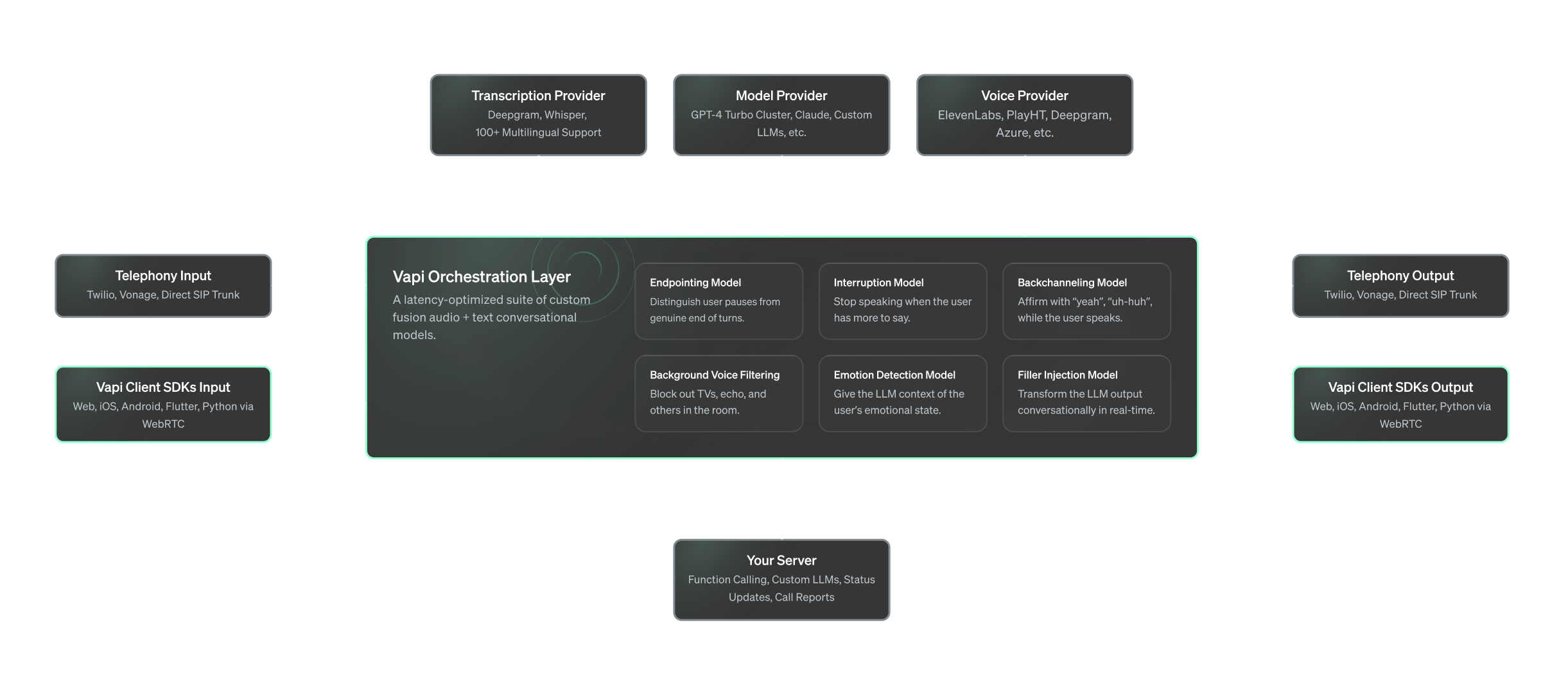
Vapi supports, maintains, and optimizes this full voice AI pipeline so you don’t have to.Let’s take a closer look at what Vapi does:
Support and Optimization
To provide you and your customers with a superior conversational experience, we have various
latency optimizations like end-to-end streaming and colocating servers that shave off every
possible millisecond of latency. We also manage the coordination of interruptions, turn-taking,
and other conversational dynamics.
Customizable
We built-in many smaller features to give developers a lot of room to customize and integrate.
For example, there’s no need for you to hook up Twilio websockets or build bidirectional audio
streaming. Instead, you can connect to the WebRTC stream through our
Web, iOS, or
Python clients…and then get right back to what you were
doing.